Our previous Scraper API on APILayer was a huge success. It's been a bestseller for more than 6 months until now and we've scraped tens of millions of pages succesfully. Now we've pushed the limits even higher with our brand new Advanced Scraper API.
This API can simulate a real browser (using headless Chromium clients), so that it can scrape web pages built with Angular, React and Vue. Let's see what this API is capable of with details.
- Rotating Proxy built in. You can select the originating IP address with a parameter. If you don't select a country from one of the 170 countries we support, we'll randomly select one and it'll be hard to trace your footprints.
- JS Execution. Ability to execute a Javascript on the remote page and return the result. We can execute any JS code, as long as it is valid and executable.
- CSS Selectors. No need to scrape the whole page and parse it. Just give us a CSS selector (e.g. 'div.logo img') and we'll scrape the page, parse it for you and return only the requested info
- Wait for navigation. If you've submitted a form using Javascript, you'll need to wait for the result page to load. Setting this flag to true will simulate this behaviour for you and scrape the result page
- Ability to set any HTTP header. Just prefix any header with an "X-" and make your request. We'll pass those headers for you to the remote site. Yes you can set HTTP auth, cookies and any other relevant information using this feature.
- Scrape images and text files. You don't need to scrape HTML source everytime. Just point your url to an image file and we'll scrape that for you
- and yes... it can scrape Amazon, Google and a lot more sites.
Basic Usage
Scraping a web page is as simple as running the following sample.
curl --location \
--request GET 'https://api.apilayer.com/adv_scraper/scraper?url=apilayer.com&country=fr' \
--header 'apikey: API KEY'
This code will fetch an IP address from France and scrape apilayer.com web page returning the following JSON result.
{
"url": "http://apilayer.com",
"request_headers": {
"USER-AGENT": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:79.0) Gecko/20100101 Firefox/79.0",
"UPGRADE-INSECURE-REQUESTS": "1",
"SEC-FETCH-USER": "?1",
"ACCEPT": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"ACCEPT-LANGUAGE": "en-US,en;q=0.9,tr;q=0.8",
"DNT": "0",
"TE": "trailers",
"Referer": "https://www.google.com"
},
"options": {
"country": "fr",
"selector": null,
"render": false,
"timeout": 30
},
"response_headers": {
"Date": "Tue, 17 Nov 2020 21:22:02 GMT",
"Content-Type": "text/html; charset=utf-8",
"Transfer-Encoding": "chunked",
"Connection": "keep-alive",
"Set-Cookie": "__cfduid=...0qg9rtOM; HttpOnly; Path=/",
"vary": "Cookie",
"Expires": "Tue, 17 Nov 2020 21:22:02 GMT",
"Cache-Control": "private",
"CF-Cache-Status": "DYNAMIC",
"NEL": "{\"report_to\":\"cf-nel\",\"max_age\":604800}",
"Strict-Transport-Security": "max-age=0",
"Content-Encoding": "gzip"
},
"data": "<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n<title>APILayer - Hassle-free API marketplace</title>\n<meta charset=\"utf-8\" />\n<meta name=\"viewport\" content=\"width=device-width, initial-scale=1, shrink-to-fit=no\" />\n<meta name=\"description\" content=\"Highly curated API marketplace with a focus on reliability and scalability. Allows software developers building the next big thing much easier and faster.\" />\n<link rel=\"shortcut icon\" href=\"/assets/favicon.ico\" />\n<link rel=\"stylesheet\" href=\"https://fonts.googleapis.com/css?family=Open+Sans:400,600&display=swap\">\n<meta name=\"twitter:card\" content=\"summary\" />\n<meta name=\"twitter:site\" content=\"@apilayer\" />\n<meta name=\"twitter:creator\" content=\"@apilayer\" />\n<meta property=\"og:title\" content=\"APILayer | Hassle-free API marketplace\" />\n<meta property=\"og:description\" content=\"API marketplace and ready to run app backends for your mobile app and website.\" />\n<meta property=\"og:image\" content=\"/assets/logo/square_large_bg.png\" />\n\n.......</html>"
}
Do not worry about generating random User Agents and fingerprinting. We'll deal with that task automatically generating a random User agent each time you're making a request. Also you don't need to specify a country each time you're making a request. Just leave it blank to fetch a random IP address from a random country to make the scraping request. (We do not charge this functionality seperately. It is built in.)
How to turn browser rendering on.
In order to scrape some client heavy sites using Angular, React or Vue you'll need to simulate a real browser. It's a really complicated task to scale this and we've spent numerous hours and built expertise on this space for years. We're triggering a Headless Chromium instance on our Docker instances running on the Cloud and scale up/down lightning fast to process your requests.
Turning on browser rendering is pretty easy. Just set the render=true query parameter and that's it. See the following code.
curl --location \
--request GET 'https://api.apilayer.com/adv_scraper/scraper?url=apilayer.com&render=true' \
--header 'apikey: API KEY'
But be warned that, your requests will slow down dramatically as a new browser instance with a GUI will be instantiated for each time you're making a scraping request.
How to execute JS code on the remote site
This is an extremely powerful feature that will allow you to control any UI feature on the remote page. For example you can type text into inputs, click buttons, hover on menus and even submit forms. You can simulate any user behaviour by typing Javascript as it'll be executed on the remote page. See the following example.
curl --location --request POST 'https://api.apilayer.com/adv_scraper/js_exec?url=apilayer.com' \
--header 'apikey: YOUR API KEY' \
--header 'Content-Type: application/javascript' \
--data-raw 'var w = window.innerWidth;
var h = window.innerHeight;
return '\''window width:'\'' + w + '\'', window height:'\'' + h;'
The result for this call will be similar to what we see below
{
"url": "https://www.kite.com/python/answers/how-to-send-a-post-request-using-urllib-in-python",
"js_code": "var w = window.innerWidth;\r\nvar h = window.innerHeight;\r\nreturn 'window width:' + w + ', window height:' + h;",
"js_result": "window width:1920, window height:1080",
"options": {
"wait_for_navigation": false,
"timeout": 30,
"country": "us"
},
"data": "<html..."
...
}
How to use CSS Selectors?
When a remote web page is fetched by default, whole HTML is returned as String. If you wish us to parse the HTML automatically and just return a specific portion of the data you can set a selector parameter and the API will parse the HTML and just return the desired info. See the following example:
curl --location \
--request GET 'https://api.apilayer.com/adv_scraper/scraper?url=apilayer.com&selector=%23logoAndNav%20a.navbar-brand' \
--header 'apikey: API KEY'
Please note that the selector parameter is URLEncoded since some CSS selectors (such as # character) may confuse the URL parameters. The result for this query is below. Please note that not the whole apilayer.com homepage is fetched. Instead just the A tag with the logo exists in the returning data, thanks to the #logoAndNav a.navbar-brand CSS selector.
{
"data-selector": [
"<a class=\"navbar-brand\" href=\"/index\">\n <img src=\"https://.../assets/logo/logo.png\"/>\n</a>\n"
],
"headers": {
"Date": "Sun, 06 Sep 2020 09:48:32 GMT",
"Content-Type": "text/html; charset=utf-8"
},
"url": "http://apilayer.com",
"selector": "#logoAndNav a.navbar-brand"
}
Image files scraping
The Scraping API is capable of fetching the image files and returning them back to you. Just point the url to an image file and see for yourself. This is one of the most powerful features of this API, which is quite rare among our competitors.
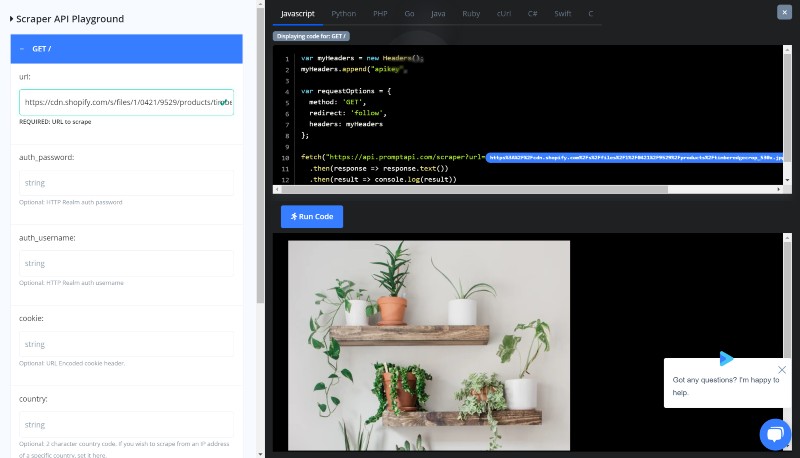
Although it can also download JSON files, TXT files and other text formats. it doesn't support application/octet-stream and any other binary formats because of security and scalability concerns.
Rotating IP addresses
We use anonymizer proxy servers, as well as our own infrastructure to change the IP addresses, as well as the HTTP request header information each time you make a new request. We utilize more than 1 million "data center" IP addresses from over 100 countries to route your request through.
There are many reasons why you need this API for web scraping:
- It helps you to overcome IP fingerprinting and rate-limiting problems
- It saves you from getting your original IP banned due to high volume of requests
- Ability of setting originating country allows you to see geography specific content
Setting Custom HTTP Headers
You may wish to set your custom HTTP Headers with your request and our Scraper API lets you do so. You can set any header by just prefixing X- to the name of the header and API will remove the X- prefix and pass it to the remote site. For example if you wish to set your custom User-Agent, Referer and Content-Type take the following example (if nothing is set, we auto generate these headers)
curl --location --request GET 'https://api.apilayer.com/adv_scraper/scraper?url=apilayer.com' \
--header 'X-Content-Type: application/json' \
--header 'X-User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0' \
--header 'X-Referer: https://www.google.com' \
--header 'apikey: YOUR_APILAYER_API_KEY'
As you see Content-Type, User-Agent and Referer headers are prefixed by a X- string. You can set any header as you wish, such as Cookie, Api Key, Languages or anything you desire. Take a look at a full list of HTTP Headers on Mozilla site.